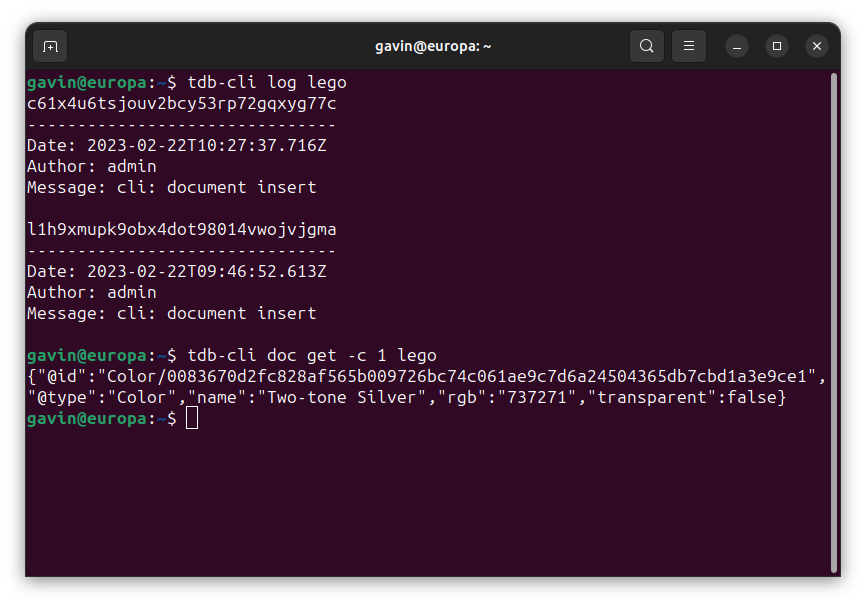




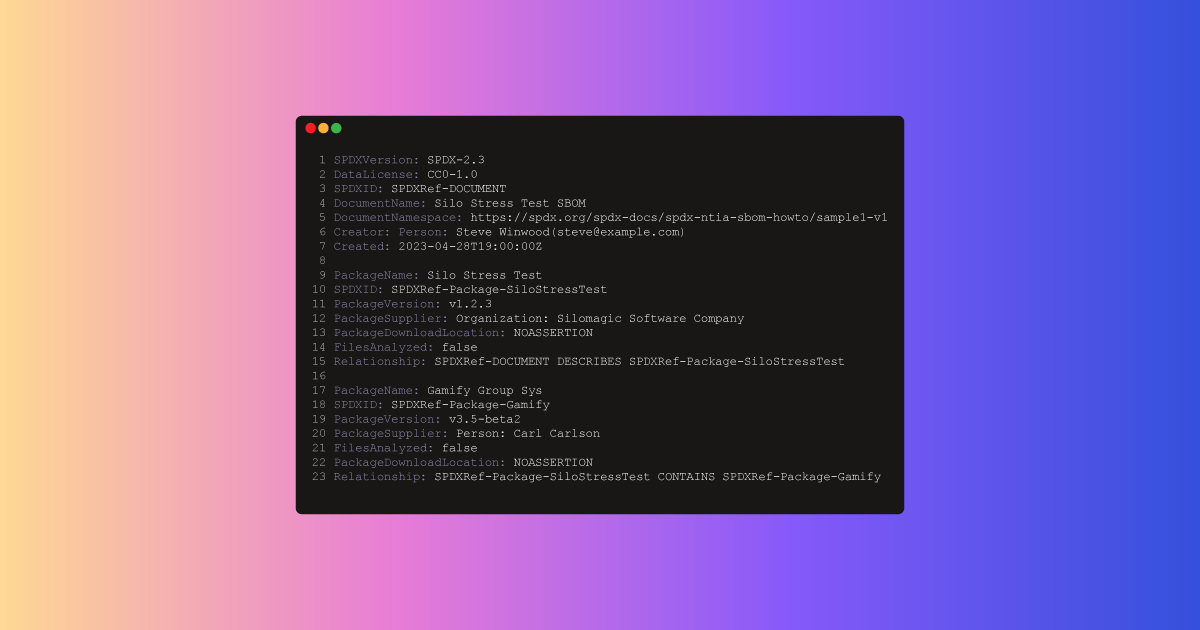
An SBOM identifies, tracks, and maintains a list of all the software components and dependencies, this article looks at how headless CMS is a good solution to manage this process.

Using declarative logic and semantic descriptions, we build a low-code app for straight-through processing of insurance claims.
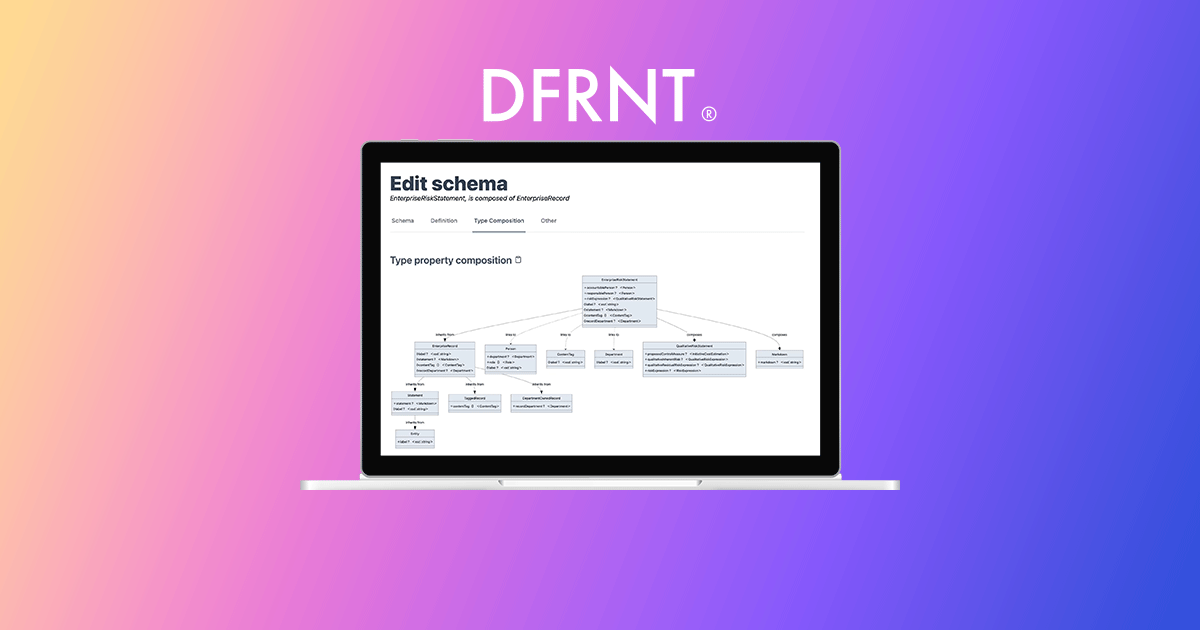
DFRNT is a tool for change makers to model and build data products. With advanced data modelling and graph visualisation, data architects can tackle complex problems.
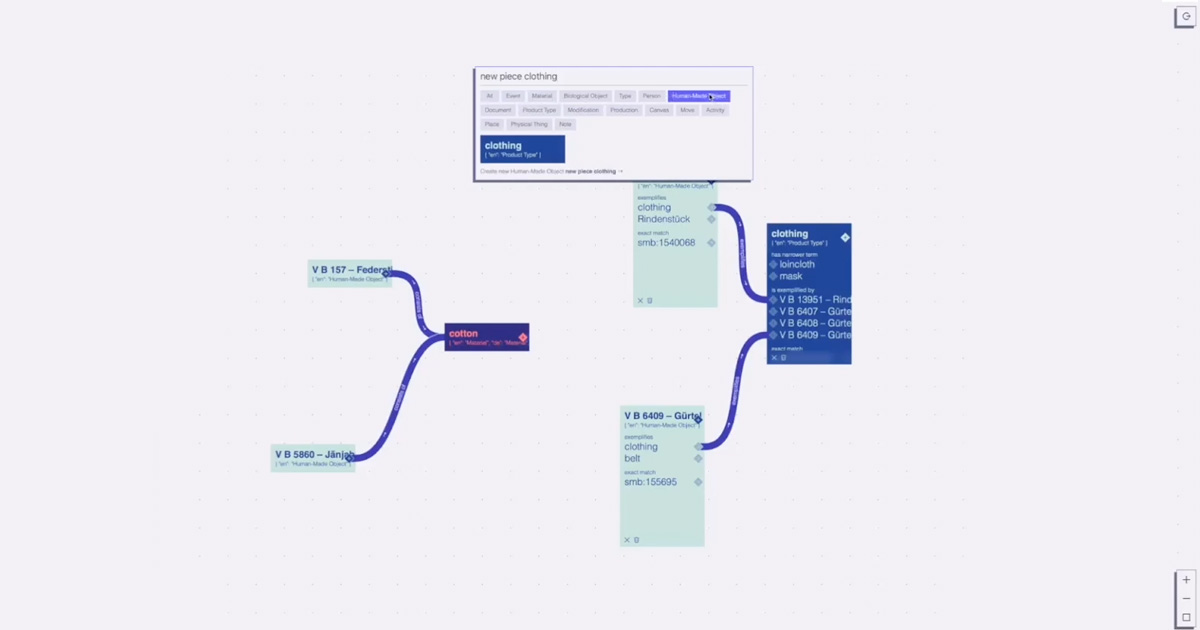
See how TerminusDB is used as an academic research database by Amazonia Future Lab to connect collections & local knowledge.

TerminusX has been developed as an extension to Excel. The extension is called VersionXL and solves the collaborative issues teams have when working with spreadsheets to make business decisions.

See how TerminusDB replaced a translation business's in-house approval workflow layer to implement workflow pipelines for translating documents into a variety of languages.

Find out how TerminusDB has been implemented as the document graph database for a collaborative data ecosystem. It has a number of features to help collaborators upload data accurately in a more time-efficient way.
